
Transformer
Attention Is All Your Need
以往主流的序列转录(seq2seq)模型中常常基于包含Encoder与Decoder的复杂RNN或CNN,这些模型也会在Encoder与Decoder中使用Attention机制。
Transformer仅仅使用了Attention机制,完全没用到循环和卷积,将循环层换为了Multi-headed Attetion。Transformer训练速度更快,预测能力更好。
Advantages
- RNN难以并行计算计算效率低,Transformer可并行。
- RNN带有时序信息,但在序列较长时,早期的信息可能在后期丢失。Attention可通过在输入序列中加入index增加时序,并且不会存在信息丢失问题。
- 用CNN可以替换掉RNN实现并行计算,但由于感受野的限制其依然存在难以对长序列进行建模的问题。Transformer中的Attention机制一次性看到所有的序列,消除了这一问题。
- CNN可利用多个输出通道识别不一样的模式,在Transformer中使用Multi-headed Attetion,也实现了这样的特性。
Model Architecture
Transformer整体分为Encoder与Decoder两大部分。
- Input Embedding/Output Embedding将词映射到向量。
- Postoinal Encoding
- Nx指有N个该块叠在一起。
- Add表示残差连接,Norm表示正则处理。
- 在训练时,解码器的输入(outputs)是真实值(Ground Truth);在测试时,输入(outputs)是前一时刻的输出。

Encoder
N=6,out_dim=input_dim=512。由两个子层组成,两个子层分别为Multi-headed Attetion和简单的MLP。每个子层使用残差连接和layer normalization。
layer normalization and batch normalization
batch:对每一个feature,将这个feature在一个batch中的所有数据的均值变为0方差变为1
layer:对每一个样本,将这个样本所有的特征均值变为0方差变为1
成sequence的normalization:
蓝为batch,黄为layer,取所有数据去做norm。阴影部分为样本实际长度(即该样本序列的seq_len),在实际长度外取全0。
使用layernormalization相对稳定一些。每个样本自己做均值方差再去norm。



Decoder
N=6,由三个子层组成,其中后两个子层Encoder一致,而第一个子层有所不同,其使用了Masked Multi-headed Attetion。在Decoder中还使用了自回归。当前的outputs输入是上一次的输出。在训练过程中,Decoder的输入outputs为ground truth,但在t时刻的输入不应包含t时刻之后的输入,所以第一个子层引入了masked机制。
Attention
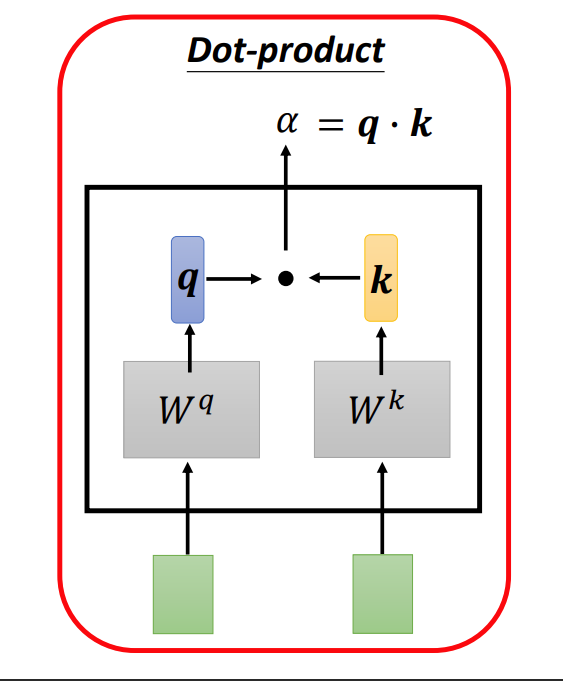
Transformer使用了Scaled Dot-Product Attention。其将输入的一个seq进行融合输出一个等长的seq。
在融合时,每一个输出都考虑了其对应位置输入元素和seq中其他元素的相关度。Wq与Wk是两个参数矩阵,原始输入做矩阵运算后得到两个向量q、k,最后用内积运算即得到了原始输入的相关性(内积运算代表了余弦相似度)。
同理可计算出a1与自身及序列中所有元素的相关性,全部计算完成后输入到softmax层进行归一化。
利用一个新的参数矩阵Wv获得v1-v4。v与相关性系数的带权和得到b1。
同理,可以得到b2、b3、b4。
上述步骤可表示为矩阵运算。
最终的计算公式可如下表示。这里多了一个除以根号dk(input_dim),这是因为向量(Transformer中dk=512)比较长时,内积绝对值可能会出现比较大的情况,这对梯度下降是不利的。




Multi-headed Attetion可以看作是多通道的Attention。以2heads为例,计算过程如下,增加了多个参数矩阵。
在最后,将bi1与bi2一起其他的相应多通道b在特征维度拼接起来,为保证dim不变,利用一个新的参数矩阵Wo将输出元素的维度变为和输入相同。
一个线性层就可看作一个参数矩阵,所以上述两步操作可看作如下的过程。


Cross Attention in Transformer
Cross Attention指的是Encoder与Decoder之间的Attention机制。其V和K来自于Encoder,而Q来自于masked Attention。由于是masked,向Q输入的部分其seq_len会与V和K的不同,又因为其作为Q输入,所以cross-attention输出的seq_len会与之相同,所以Decoder的输入输出seq_len是相同的。
Feed-Forward
只有一个MLP分别去作用于seq中的每个词,
图中MLP权重是相同的,也不需要把Encoder的输出合并输入到大的MLP。因为这里只是想要把原始维度投影到想要的另一个维度,其信息融合已经在Encoder中做完了。
Embedding and Softmax
编码器要有embedding,解码器要有embedding,softmax层之前有一个Liner层,这三个层共享权重。
Positional Encoding
为了给Attention加上时序信息,给输入加上位置信息。