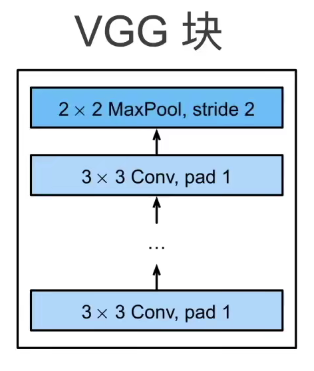
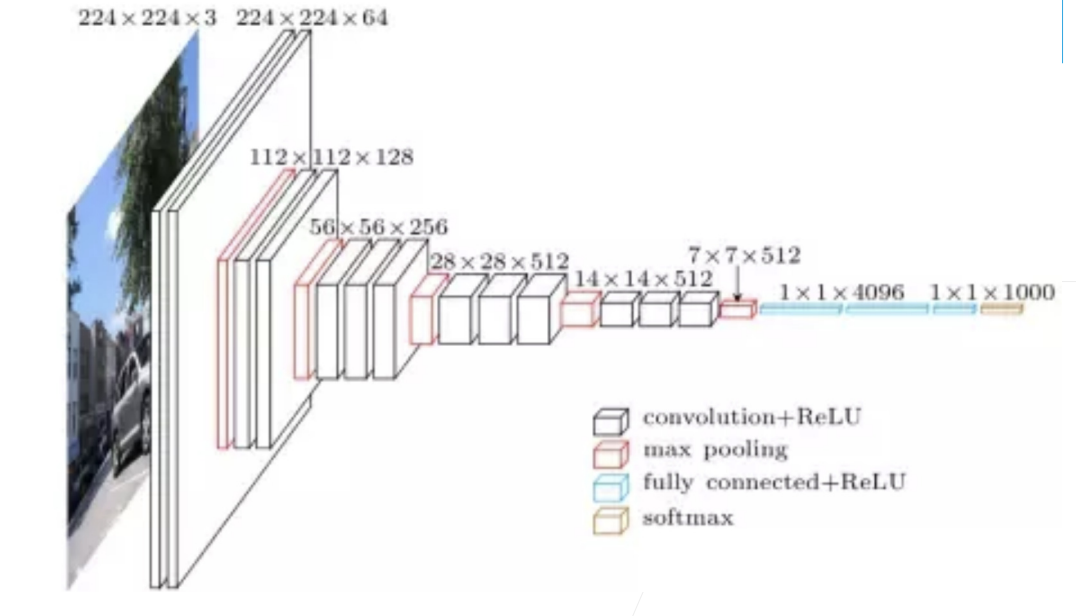
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import torch
from torch import dropout, nn,optim
import d2l
def vgg_block(num_convs,in_channels,out_channels):
layers=[]
for _ in range(num_convs):
layers.append(
nn.Conv2d(in_channels,out_channels,3,padding=1)
)
layers.append(nn.ReLU())
in_channels=out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
def vgg_architecture(num_blocks,in_channels):
blocks=[]
out_channels=16
blocks.append(vgg_block(1,in_channels,out_channels))
for _ in range(num_blocks-1):
in_channels=out_channels
out_channels*=2
blocks.append(vgg_block(1,in_channels,out_channels))
return nn.Sequential(*blocks)
def vgg_5(in_channels):
return nn.Sequential(
vgg_architecture(5,in_channels),
nn.Flatten(),
nn.Linear(256*7*7,1024),
nn.Dropout(),
nn.Linear(1024,512),
nn.Dropout(),
nn.Linear(512,10)
)
vgg=vgg_5(1).to(torch.device("cuda:0"))
train_iter,test_iter=d2l.load_data_fashion_mnist(64,224)
loss_f=nn.CrossEntropyLoss()
opt=optim.Adam(vgg.parameters())
d2l.train(10,loss_f,opt,vgg,train_iter,save_name="vgg_5")
|