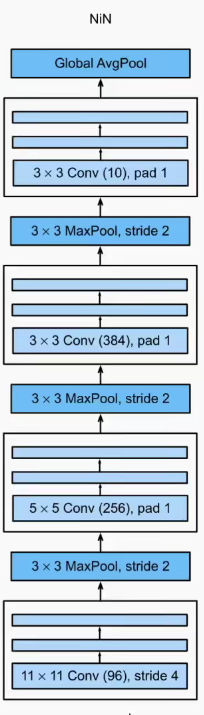
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import torch
from torch import nn,optim
class NiNBlock(nn.Module):
def __init__(
self,in_channels,out_channels,
kernel_size,stride,padding
):
super().__init__()
self.conv=nn.Conv2d(
in_channels,out_channels,kernel_size,
stride=stride,padding=padding
)
self.f1=nn.Conv2d(out_channels,out_channels,1)
self.f2=nn.Conv2d(out_channels,out_channels,1)
self.relu=nn.ReLU()
def forward(self,x):
x=self.relu(self.conv(x))
x=self.relu(self.f1(x))
x=self.relu(self.f2(x))
return x
nin_net=nn.Sequential(
NiNBlock(1,96,11,4,0),
nn.MaxPool2d(3,stride=2),
NiNBlock(96,256,5,1,2),
nn.MaxPool2d(3,stride=2),
NiNBlock(256,384,3,1,1),
nn.MaxPool2d(3,stride=2),nn.Dropout(),
NiNBlock(384,10,3,1,1),
nn.AdaptiveAvgPool2d(1),
nn.Flatten()
)
loss_f=nn.CrossEntropyLoss()
opt=optim.Adam(nin_net.parameters())
import d2l
train_iter,test_iter=d2l.load_data_fashion_mnist(128,resize=224)
d2l.evaluate(
nin_net,test_iter,loss_f,
"D:/code/machine_learning/limu_d2l/params/NIN_5",
device=torch.device("cuda:0")
)
|