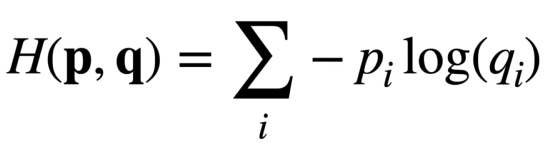1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
num_inputs=1*28*28
num_outputs=10
w=torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True)
b=torch.zeros(num_outputs,requires_grad=True)
def Softmax(X):
X_exp=torch.exp(X)
partition=X_exp.sum(1,keepdim=True)
return X_exp/partition
def CrossEntropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y]).sum()
def Net(w,b,X):
return Softmax(torch.matmul(X,w)+b)
def Sgd(params,lr):
with torch.no_grad():
for i in params:
i-=lr*i.grad
i.grad.zero_()
def Train():
for epoch in range(50):
loss=0
for X,y in train_iter:
X=X.view(-1,784)
out=Net(w,b,X)
l=CrossEntropy(out,y)
l.backward()
Sgd([w,b],0.0001)
loss=l.item()
print(f"{epoch},{loss}")
|