
D2L: Perceptron
Perceptron
Concept and Principle
- 感知机
- 模型
感知机只比线性分类多了一个激活函数,激活函数为单层感知机带来了分类能力,为多层感知机带来了非线性因素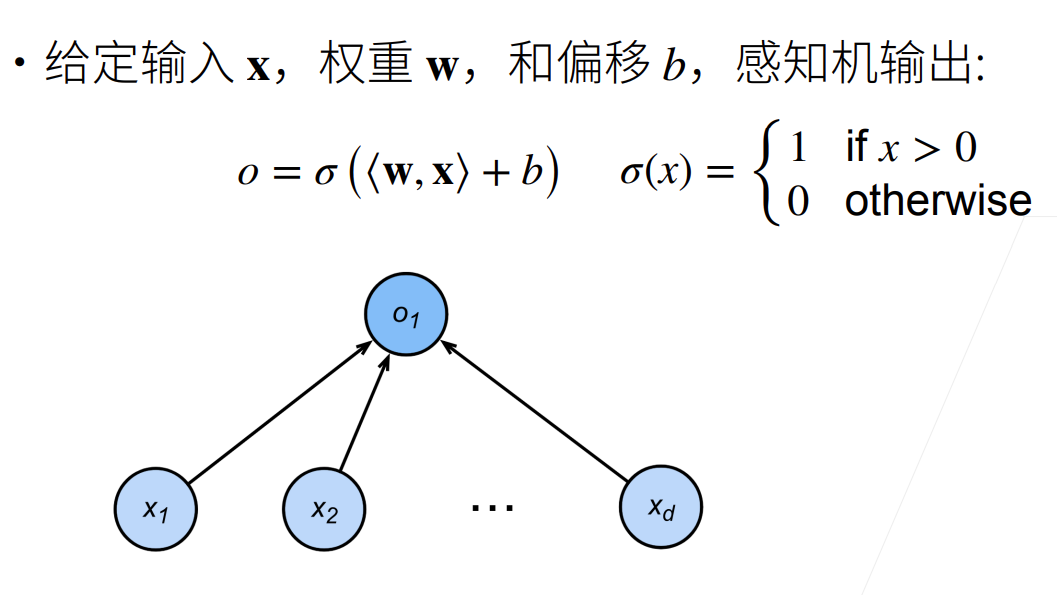
- 训练
训练感知机等价于批量大小为1的梯度下降,按顺序逐个取样本,与随机梯度下降不同
- 单层感知机无法解决异或问题,他只能产生线性分割面,这导致了第一次AI寒冬
- 模型
- 多层感知机
- 多层感知机由多个感知机组成,分为输入层、隐藏层、输出层,层内不连接,层间全连接
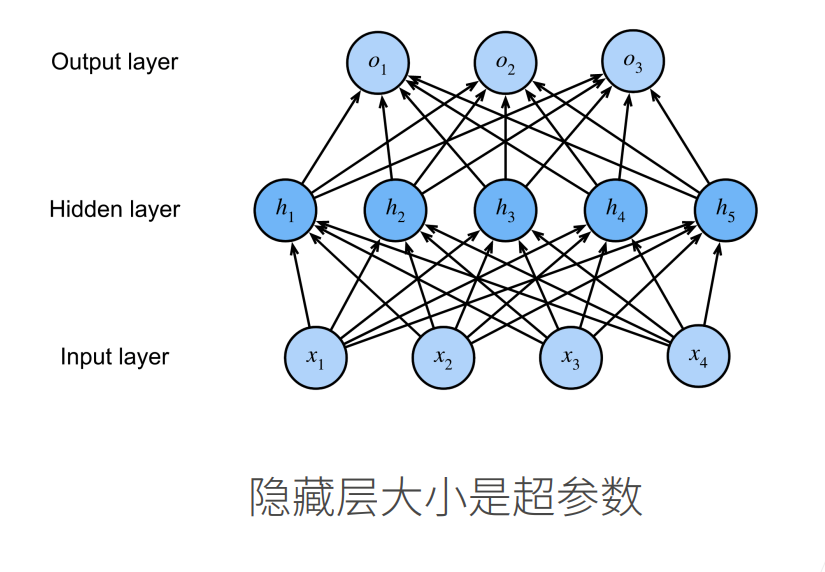
- 每个感知机输出后要经过一个非线性的激活函数,否则多层感知机等价于单层感知机
- 常用激活函数:Sigmoiod、Tanh、ReLU,性能都没太大区别,ReLU计算更容易,如果没有特别的想法,用ReLU就行
- 多层感知机由多个感知机组成,分为输入层、隐藏层、输出层,层内不连接,层间全连接
Implementation
- 从零实现
1 | |
Comment