
D2L: Modle Selection
Modle Selection
Concept and Principle
- 训练误差和泛化误差
- 训练误差:模型在训练数据上的误差(不太关心)
- 泛化误差:模型在新数据上的误差(很关心)
- 验证数据集和测试数据集
- 验证数据集
用于在训练过程中评估模型好坏的数据集,一般从训练集中划分出一部分,验证数据集不能作为训练集让模型训练,用来动态调整模型超参数 - 测试数据集
模型最终训练完毕后,使用测试集测试模型泛化能力,不能使用测试集来调整模型超参数,大多数情况下不会被打上标签
- 验证数据集
- K-折交叉验证
通常情况下,我们都没有足够富裕的数据去从训练集中划分验证集,这是使用K-折交叉验证能较简单的解决问题- 思想:一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。找到后,在全部训练集上重新训练模型,并使用独立验证集对模型性能做出最终评价。
- 算法:K折就将训练集分为K块,训练代价为原来的K倍
- 将原始数据集划分为相等的K部分(“折”)
- 将第i部分作为验证集,其余作为训练集
- 训练模型,计算模型在验证集上的准确率
- 每次用不同的部分i作为验证集,重复步骤2和3 K次
- 将平均准确率作为使用当前超参时的模型准确率
- 找到一个较好的超参数后,再用全部训练集训练模型,并在一个全新的验证集上验证,不用调超参数,达到一个较好的验证准确率时,直接去测试
- 过拟合和欠拟合
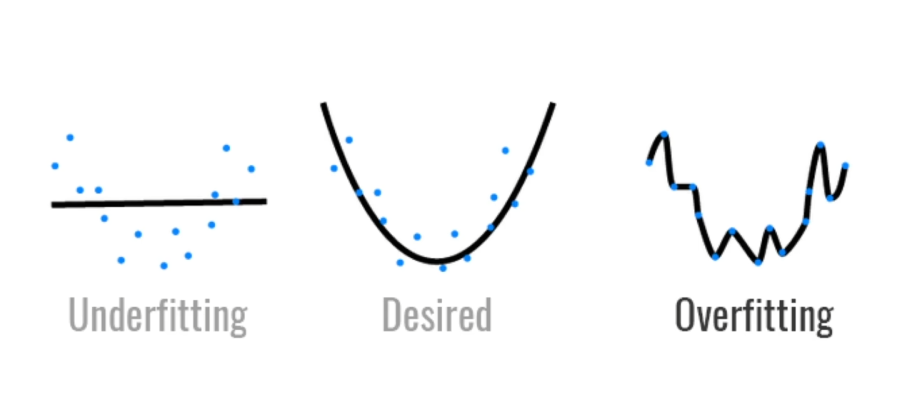
- 模型容量的影响
数据集复杂程度应该与模型复杂程度正相关,否则就会出现过拟合与欠拟合。举例来说,当模型很复杂而数据很简单时,模型可以直接就把所有数据记住而丧失泛化能力;而模型过于简单时,如感知机模型,无法正确划分异或的数据
模型足够复杂时,有其他手段减少过拟合;模型太简单没前途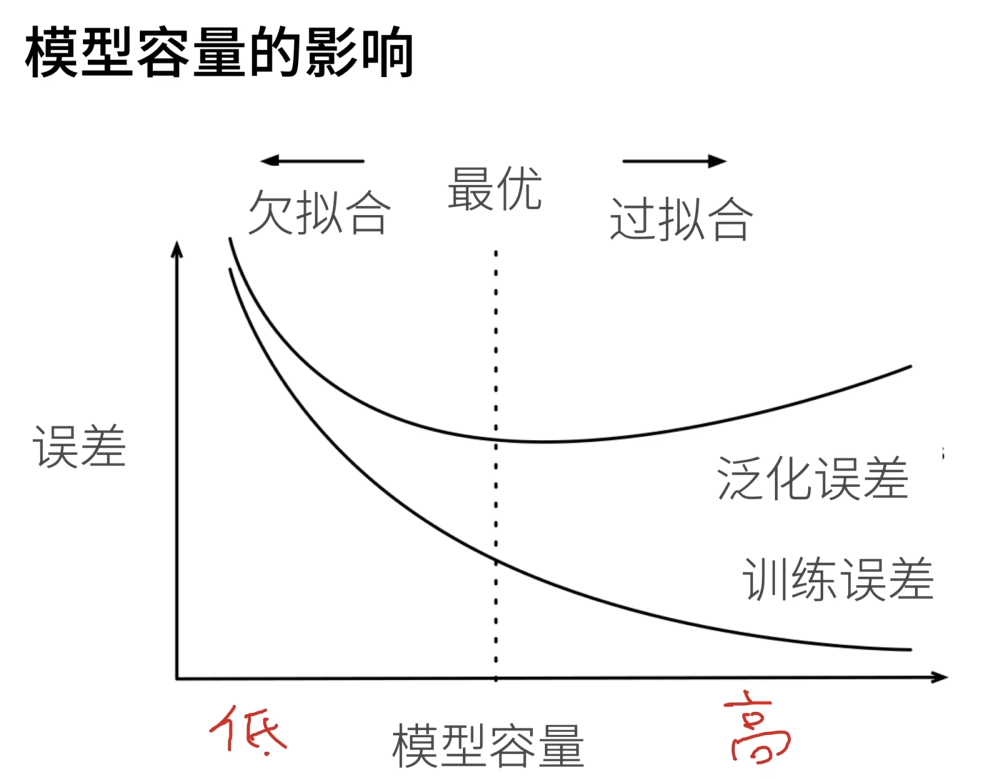
- 模型容量的影响
- 估计模型容量
模型种类确定时(如神经网络),模型容量由两个因素估计:参数个数、参数取值范围 - 数据复杂度
有多个重要因素:- 样本个数
- 特征个数
- 时间、空间结构
- 多样性
Comment